출처 : <c언어로 쉽게 풀어쓴 자료구조> + 학교 수업
<전체 코드>
#include<stdio.h>
#include<stdbool.h>
typedef struct {
int data;
struct node* link;
}node;
node* insert_first(node* head, int x) {
node* p = (node*)malloc(sizeof(node));
p->data = x;
p->link = head; //head는 노드 생성을 안했으니까 head->link 연산이 안 됨
head= p;
return head;
}
node* insert(node* head, node* pre, int s) {
node* p = (node*)malloc(sizeof(node));
p->data = s;
p->link = pre->link;
pre->link = p;
return head;
}
int main() {
node* head = NULL;
//데이터 삽입 및 출력
for (int i = 0; i < 5; i++) {
head = insert_first(head,i); //반환된 head 포인터를 저장. 아니면 null값만 출력됨
print_node(head);
}
return 0;
}
#구조체


연결리스트의 각 노드가 될 설계도인 구조체. data는 int형이니까 4byte고, link는 포인터 형이니까 2byte로 구조체는 총 6byte가 된다.
#데이터 삽입1(insert_first)


1. 일단 자료형이 node인 포인터 변수 head를 NULL로 초기화 해준다.
2. (83줄) 대입 연산자(=)의 오른쪽부터 시작하니까, insert_first함수를 호출한다.
3. malloc함수를 통해 데이터를 동적으로 할당한다.



마지막에 캐스팅은 malloc함수로 메모리를 할당하게 되면, 사이즈만 있고 무슨 자료형인지 알 수 가 없어서 하게 된다. 즉, node형을 가리키는 값을 저장할 수 있게 되는 것이다.
아무튼 여기까지 오면 메모리는 아래 그림과 같은 상태가 된다.

메모리 구조에 대해서는 www.tcpschool.com/c/c_memory_structure여기에 잘 나와있다. 이런 걸 굳이 알아야 되나 싶을 수도 잇는데, 코딩 실력이 느는 지름길은 내가 cpu라고 생각하고 코드를 짜는 것이라고 교수님께서 말씀하셨다.
아무튼 대충 요약하자면 컴퓨터의 메모리에는 스택 영역과 힙영역이라는게 있는데, 스택 영역에는 지역변수와 매개변수, 힙영역에는 동적변수(malloc으로 생성한 변수)가 저장된다. 이해가 잘 안 된다면 손으로 직접 그려보는 것을 추천.
4. 11줄, 12줄을 통해서 새로 생성된 노드에 각각 data와 link값을 넣어준다.
(여기서 실수한 게, head->link를 썻던 거. 현재 head는 NULL이기 때문에 가리키는 노드가 없어서 그런 연산을 사용할 수 없다.)

5. head값을 return하면 insert_first()는 종료되고 그 안의 변수들은 메모리에서 사라지게 된다.

(당연하게도 모든 변수에는 메모리 주소값이 있고 당연히 10'가 아니라 임의의 값이다. 귀찮아서 필요한 곳에만 주소값을 쓸껀데, 매개변수 head(100')에다가는 왜 썻는지 모르겠다.. 바본가...)
아무튼 이 과정을 계속 반복하다보면 아래와 같은 형상이 나올거다. 이걸 일일이 손으로 쓰다보면 연결리스트에 대한 이해가 더 빠르게 되니까 해보는 거 추천.

#데이터 삽입2(insert)
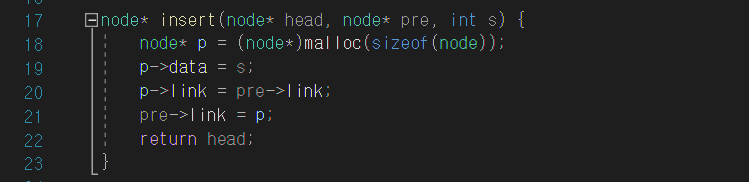
이건 책에서 연산하는 건 안 보여줘서 내가 대충 이렇게 돌아가겠거니~하면서 설명해보려 한다.
insert는 가장 일반적인 연산이라고 한다. ( insert_first가 연결리스트의 맨 앞에만 추가 된다면 insert는 연결리스트 중간에 추가된다. )

이 연산을 하려면 일단 pre라는 포인터가 필요하다. 이 포인터는 새로 생성할 노드가 들어갈 자리의 전 노드를 가리키는 포인터이다. 만약에 위의 그림에 10'다음에 노드를 추가하려면 pre는 10'를 가리키고 잇어야 한다.

일단 기본이 이렇게 되있다고 가정한다. 새로운 노드는 20'다음에 추가한다.
1. 18줄- 새로운 노드를 생성한다.

2. 데이터를 삽입하고, p->link에는 pre가 가리키는 노드의 link필드에 위치한 값 즉, 40'를 넣는다.

3. 마지막으로 pre->link에 현재 p값 즉, 30'를 넣어주면 끝이다. 그리고 head값을 리턴하고 함수를 종료하면 insert 함수에 있던 모든 지역변수와 매개변수는 메모리상에서 사라진다.

그리고 이제 봤는데 메인 함수에서 i에 2를 썻어야 됐는데 0이라고 써놨다. 0이 아니라 2다...
덧붙여서 head를 일일이 return하지 않고 할 수 있는 방법도 있다. 바로 이중 포인터를 사용하는 것! 이는 다른 글에서 포스팅 하겠다.
단일 연결리스트는 자료구조의 기본 중 기본이다. 이후에 해쉬나 트리를 배울 때도 사용하니 잘 알아둬야 한다.(라고 교수님께서 말씀하셨다.)
자료구조는 어려울 수도 있는 과목이지만 이렇게 그림을 계속 그리다보면 이해도 쉽고 나중에가서는 그림 그리면서 코드도 혼자 짤 수 있게 된다. 연구실 들어오고 복전 시작하기 전까지 이런 방법을 몰라서 코드를 무식하게 외웠다..
'C > 자료구조' 카테고리의 다른 글
| 문과생이 이해한 이중 연결리스트 (0) | 2021.04.26 |
|---|---|
| 문과생이 이해한 원형 연결리스트 (0) | 2021.04.26 |
| 문과생이 이해한 단일 연결리스트(이중 포인터 사용) (0) | 2021.04.11 |
| 문과생이 이해한 단일 연결 리스트(기타 연산- 합병, 역순, 출력/순회, 탐색) (0) | 2021.04.10 |
| 문과생이 이해한 단일 연결 리스트(삭제 연산) (0) | 2021.04.10 |



