[pytorch] 문법 3부작 中 1부. tensor 연산 츄베릅❤️
출처: https://youtu.be/k60oT_8lyFw?si=lJU8cErzTzAVjtlz
0. 정의
- pytorch?
(페이스북에서 만든) gpu를 이용한 텐서 조작 및 동적 신경망 구축이 가능한 딥러닝 프레임워크.
* 라이브러리 vs 프레임워크
- 라이브러리는 사용자가 어느 정도 제어권을 갖지만, 프레임워크는 뼈대 안에서만 활용할 수 있습니다.(제어 역전이라고도 함)
- 제가 느끼기로는, 둘 다 타인이 만든 코드의 집합이라는 점에서 공통점이 있습니다. 차이점이라면, pytorch의 함수(dataloader 등)는 새로운 기능을 하게 만들기 어렵습니다. 하지만 numpy는 sum() 등 여러 함수들을 이용해서 새로운 기능을 하는 만들어 내기 수월하다는 점입니다. 물론 pytorch에도 tensor 연산(sum 등) 기능이 있습니다. 그치만 ndarray가 tensor보다 여러모로 가공이 수월하다는 장점이 있죠.
- 자세한 내용은 아래 블로그 참고해주세요.
- Tensors?
1) 데이터를 담기 위한 컨테이너, 다차원에 대한 표현 방법 => 표현은 거창하지만 대충 배열이라고 생각.
2) 일반적으로 수치형 데이터 저장
- 왜냐면 신경망 학습은 컴퓨터 이해할 수 있는 수치형 데이터만 할 수 있으니까!
3) numpy- ndarray와 유사
=> ndarray vs tensor
1. tensor- 가속기 메모리(GPU, TPU와 같은)에서 사용 가능
2. tensor- 불변성(immutable)을 가짐=> 텐서플로우 공식 홈에서 이래 말하기는 하는데 잘 모르겠음
3. tensor보다 ndarray가 image, 시각화 연계, 데이터 가공에서 다루기 쉬움
1. 텐서
1.1 텐서 초기화와 데이터 타입=> 생략
# 보통 많이 쓸 거라 생각되는 방법
data = [[1, 2], [3, 4]]
x_data = torch.tensor(data)
# ndarray로부터 변환
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
솔직히 python과 numpy 배운 분들이라면, 굳이 모두 볼 필요 없다고 생각함. 그치만 대강이라도 궁금하다면 아래 사이트에서 보는 걸 추천.
https://tutorials.pytorch.kr/beginner/blitz/tensor_tutorial.html
텐서(Tensor)
텐서(tensor)는 배열(array)이나 행렬(matrix)과 매우 유사한 특수한 자료구조입니다. PyTorch에서는 텐서를 사용하여 모델의 입력과 출력뿐만 아니라 모델의 매개변수를 부호화(encode)합니다. GPU나 다른
tutorials.pytorch.kr
1.2 cuda Tensors: device
변수.to(device, type-생략가능): 텐서를 어떤 장치(cpu, gpu)로 옮김
앞서 tensor는 gpu를 통한 가속 연산이 가능하다 말했습니다. 바로 이 방법을 쓰는거죠.
- device 설정 방법
# 보통 device 정의 방법
# gpu가 있으면 gpu쓰고, 없으면 cpu 쓰라는 뜻
# print(device)하면, 사용하고 있는 device가 출력됨
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
- tensor 옮기기
x = torch.tensor([5]) # 5
# device 설정 방법
x=x.to(device) # 5
y = torch.ones_like(x, device=device) # 1
z = x+y # 6
z.to('cpu', torch.double)
여기서 x-cpu, y-gpu일 때, x+y의 결과가 궁금했어요. gpu가 없는 관계로, chatgpt한테 물어봤는데, pytorch에서 자동으로 device를 동일한 장치(명시적으로 지정하지 않은 경우, 현재 활성화된 기기-대부분 cpu-)로 이동시켜 연산을 한대요.
1.3 다차원 텐서
1) 0D Tensors(=Scalar)
- rank(축): 0
- shape: ()
2) 1D Tensor(=Vector)
- rank(축): 1
- shape: (3,)
3) 2D Tensor(=Matrix)
- rank(축): 2
- shape: (3,3)
- 구조 : 특성(feature) + 샘플(smaples)
- ex) 수치, 통계 데이터 셋
4) 3D Tensor
- rank(축): 3
- shape: (3,3,3)
- 구조 : 특성(features) + 샘플(samples) + 타입스텝(timesteps)
- ex) 연속된 시퀀스 데이터, (시간 축이 포함된)시계열 데이터, 흑백 이미지
5) 4D Tensor
- rank(축): 4
- shape: (3,3,3,3)
- 구조 : 샘플(smaples) + 높이(height) + 너비(width) + 컬러 채널(channel)
- ex) 컬러 이미지 데이터 (흑백은 3D Tensor로 가능)
6) 5D Tensor
- rank(축): 5
- shape: (3,3,3,3,3)
- 구조 : 샘플(samples) + 프레임(frames) + 높이(height) + 너비(width) + 컬러 채널(channel)
- ex) 비디오 데이터 (이미지가 연달아 있는 데이터)
# 2D tensor 생성
t2 = torch.tensor([[1,2,3],
[4,5,6],
[7,8,9]])
1.4 텐서의 연산=> 생략
1.1 과 같은 이유로 생략
https://tutorials.pytorch.kr/beginner/blitz/tensor_tutorial.html
텐서(Tensor)
텐서(tensor)는 배열(array)이나 행렬(matrix)과 매우 유사한 특수한 자료구조입니다. PyTorch에서는 텐서를 사용하여 모델의 입력과 출력뿐만 아니라 모델의 매개변수를 부호화(encode)합니다. GPU나 다른
tutorials.pytorch.kr
1.5 텐서의 조작=> 일부 생략
1) view: 텐서의 크기(size)나 모양(shape) 변경
x = torch.randn(4,5)
y = x.view(20)
z = x.view(5,-1) # -1 : 나머지는 알아서 계산

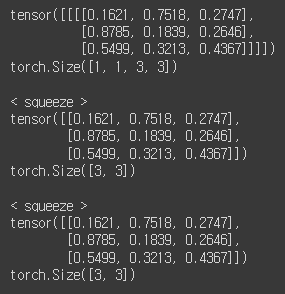
2) squeeze: 차원 축소(제거)
tensor = torch.rand(1,3,3)
print(tensor)
print(tensor.shape)
print()
print('< squeeze >')
t = tensor.squeeze() # 호잇쨔~
print(t)
print(t.shape)
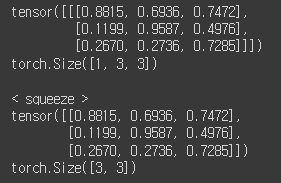
이거는 근데 size가 1인 경우만 squeeze가 되는 거 같아요.
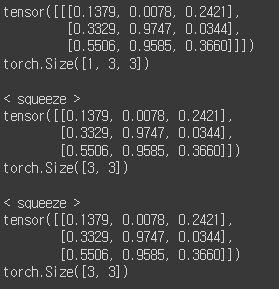
아 그리고, 축소할 수 있는 축이 있으면 한 번에 다 짜버리네요.
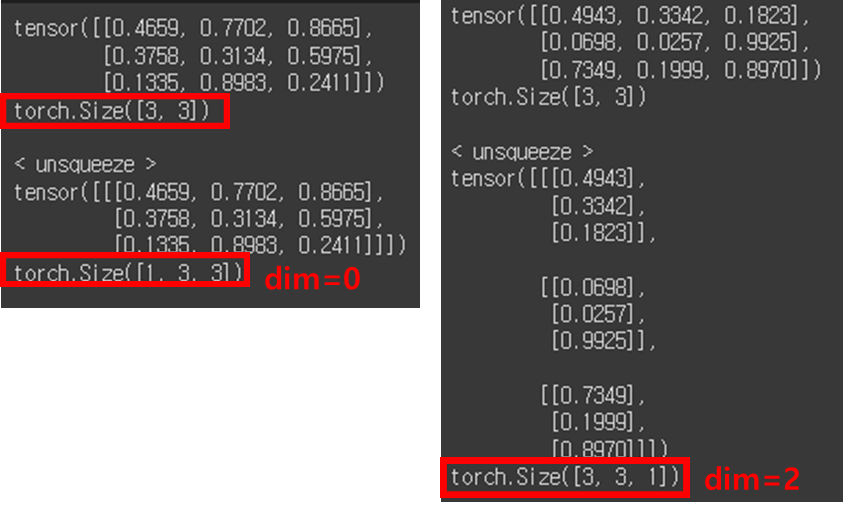
3) unsqueeze: 차원 증가(생성)
tensor = torch.rand(3,3)
print(tensor)
print(tensor.shape)
print()
print('< unsqueeze >')
t = tensor.unsqueeze(dim=0) # 축=0
print(t)
print(t.shape)
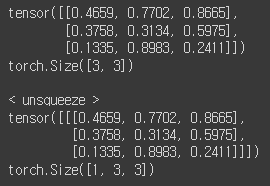
축 설정하는 거에 따라 모양이 달라집니다.
4) 텐서 결합: stack, cat
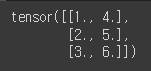
- stack
x = torch.FloatTensor([1,4])
y = torch.FloatTensor([2,5])
z = torch.FloatTensor([3,6])
torch.stack([x,y,z])
- cat(concatenate)- stack와 유사하지만 쌓을 dim(축)이 존재해야 함
a = torch.randn(1,3,3)
b = torch.randn(1,3,3)
print(a); print(b)
print()
c = torch.cat((a,b), dim = 0) # dim=0, 0번 축을 기준으로 합쳐짐
# 그래서 a와 b의 0번 축을 합쳐 2,3,3이 되는거임
print(c)
print(c.size())

축을 2로 설정하면 이래 됨.

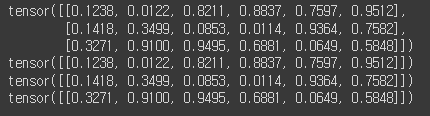
5) 텐서 나누기: chunk, split
- chunk: 텐서 개수 (몇 개로 나눌건지?)
# chunk: 텐서를 여러 개로 나눌 때(몇 개로 나눌건지?)
tensor = torch.rand(3,6)
print(tensor)
# 언패킹 하는 거니까, 왼쪽 변수 개수랑 잘 맞춰야 함
t1,t2,t3 = torch.chunk(tensor, 3, dim=0)
print(t1)
print(t2)
print(t3)
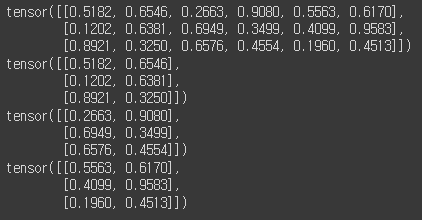
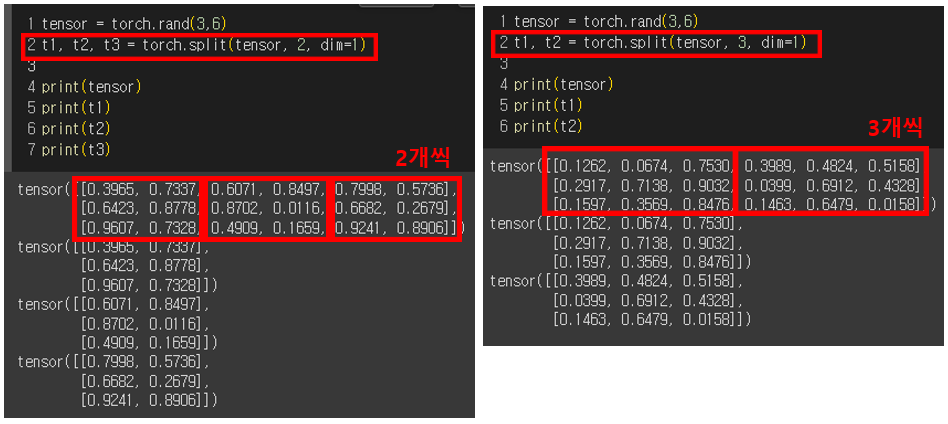
- split: 텐서 크기
tensor = torch.rand(3,6)
t1, t2 = torch.split(tensor, 2, dim=0)
print(tensor)
print(t1)
print(t2)
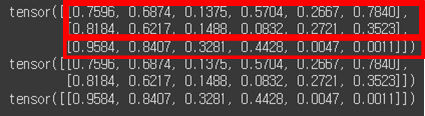
다른 예시. chunk와 마찬가지로 언패킹 하는 거니, 왼쪽 변수와 개수가 다르면 error난다.
ex) (3,6)에서 1축(=6)을 2개씩 묶을 거면 왼쪽 변수는 3개 여야 하고, 3개씩 묶을 거면 왼쪽 변수는 2개 여야함.
(+) 스칼라값.item()
x = torch.randn(1)
print(x)
print(x.item()) # 실제 값. 스칼라 값만 가능
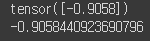
randn이 표준 정규 분포에서 무작위로 값을 생성하다보니, 실제값과의 차이가 생긴다고 합니다.

💡레퍼런스
1. tensor와 ndarray 차이1
https://www.tensorflow.org/tutorials/customization/basics?hl=ko
텐서와 연산 | TensorFlow Core
Google AI Studio에서 Gemini의 텍스트 및 이미지 추론 기능을 사용해 보세요. 빠르고 무료입니다 . Build with Gemini ,Google AI Studio에서 Gemini의 텍스트 및 이미지 추론 기능을 사용해 보세요. 빠르고 무료입
www.tensorflow.org
2. tensor와 ndarray 차이2
Tensor 타입을 Numpy로 변환하는 이유가 궁금합니다. - 인프런
모델 Inference 결과 중 value 값을 .numpy()를 통해 Numpy 형태로 변환해주는데,그 이유가 Tensor 타입에는 shape나 dtype 정보가 함께 들어있어서 이를 제외한 순수 array값만을 가져오기 위해서인가요?코드
www.inflearn.com
감사합니다.