하찮은 딥러닝
[pytorch] 문법 3부작 中 2부. 자동 미분 츄베릅❤️
소곡이
2024. 2. 1. 23:15
728x90
출처: https://youtu.be/k60oT_8lyFw?si=lJU8cErzTzAVjtlz
2. 자동 미분
2-1) torch.autograd 패키지
- tensor의 모든 연산에 대해 자동 미분이 제공되는 아름다운 코드(래요ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ)
- 코드를 어떻게 작성하여 실행하느냐에 따라 역전파가 정의된다는 뜻
- 역전파를 위해 미분값을 자동으로 계산
2-2) requires_grad = True :해당 텐서에 이루어지는 모든 연산들을 추적하기 시작
import torch
a = torch.randn(3,3)
a = a * 3
print(a)
print(a.requires_grad) # 기본 false임
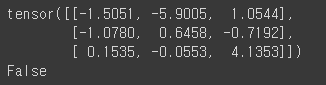
연산 기록을 추적하기 시작하면, 해당 텐서 뿐만 아니라 해당 텐서의 연산 결과 값을 가지는 텐서도 연산 기록을 추적할 수 있습니다.
a.requires_grad_(True) # 괄호 앞에 언더 바의 의미= in-place 바꿔치기
b = (a * a).sum() # 결과 : a*a 결과 값 모두 합친 값 한 개
print(b)
print("b의 연산 기록:", b.grad_fn)
print("텐서 b연산 추적 여부: ", b.requires_grad)

그리고 코드는 무조건 in-place 해야 됩니다.
3. 기울기
3-1) {텐서}.grad :기울기=미분값
텐서 x가 +연산, *연산, 평균 연산 총 3개의 layer를 거치고 역전파 이후에 미분 값을 출력합니다.
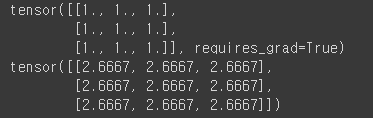
x = torch.ones(3,3, requires_grad = True)
y = x + 5 # + 연산
z = y * y # * 연산
out = z.mean() # 평균 연산
out.backward() # 역전파 계산, .grad 속성에 누적 됨
print(x) # x의 원래 값
print(x.grad) # x의 미분 값 출력
3-2) with torch.no_grad() = 기울기 업데이트 중지
코드 블록을 with torch.no_grad()로 감싸면 기울기 업데이트가 중지 됩니다. 주로, 모델을 평가할 때 쓰이죠. 왜냐면 모델 자체를 평가할 때는 모델을 업데이트하면 안 되기 때문입니다.
print(x.requires_grad) # true/false 출력 (현재는 True 상태)
print((x**2).requires_grad) # 제곱에 대해 출력
with torch.no_grad(): # with로 감싼 코드에서는 기울기 계산 하지 않음
print((x**2).requires_grad) # Flase가 출력됨

3-3) .detach(): 기록 추적 중단. 호출하면 연산기록으로부터 분리 됨.
내용물은 같지만 require_grad가 다른 새로운 tensor를 가져올 때 사용됩니다. 2-2)에서 a텐서를 requires_grad=True로 설정 했을 때 a텐서의 연산 결과를 담은 b텐서도 requires_grad=True로 자동 설정 되었죠? 그걸 방지하는 겁니다.
print(x.requires_grad) # True 상태
y = x.detach() # x를 detach한 것을 y로 지정
print("y 연산기록 상태", y.requires_grad) # False
print("x 연산기록 상태",x.requires_grad) # True
