개발 목표 : 카카오톡 대화 파일에서 빈도수가 높은 명사 추출
개발 환경 : COLAB
개발 시간 : 약 3일
사전 준비
1. konlpy 모듈을 설치. 참고로 자연어 처리 모듈로 여러가지 자연어 처리 모델이 들어있다.
!pip install konlpy
2. 코랩에서 구글 드라이브 연동하는 코드. 코랩에서 쓸 거 아니면 그냥 파일 경로 쓰면 된다.
from google.colab import drive
drive.mount('/drive')- 코랩에서 파일 경로는 사진과 같이 복사할 수 있다.

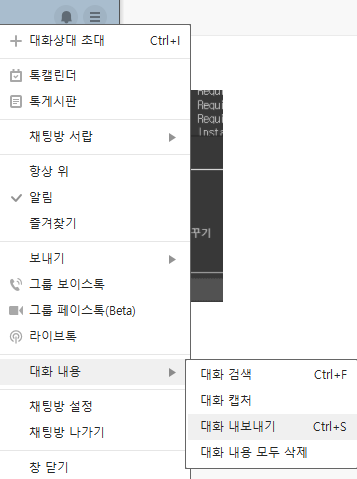
3. 카카오톡 대화 파일
세줄=> 대화내용=> 대화 내보내기
전체 코드
import pandas as pd
from konlpy.tag import Okt
import operator
file="파일 경로"
df=pd.read_csv(file, sep="\t", encoding="utf-8")
data=[]
okt=Okt()
words_freq={}
#문자열에서는 삭제할 문자가 없어도 에러 안뜨는데 리스트는 뜬다
deleteS=['ㅜ', 'ㅠ','ㅋ','ㅇ','𐌅','ㅗ'] #문자
deleteL=['이모티콘','삭제된','사진','동영상'] #문자열
#데이터 정제- 필요없는 데이터들 지우기
for i in range(len(df)):
l=df.iloc[i,0].split('] ') #리스트로 반환
if len(l)>1:
l.pop(0); l.pop(0) #날짜, 사용자 정보 제거
print(l)
for d in deleteL:
if d in l: l.remove(d)
if len(l)!=0:
result = str(l[0])
for d in deleteS: result=result.replace(d,'')
if not result.isspace() and len(result)!=0: data.append(result)
#명사만 추출+빈도수 확인
for d in data:
n_list=okt.nouns(d)
for n in n_list:
if len(n)>1:
if n not in list(words_freq.keys()): words_freq[n]=1
else: words_freq[n]=words_freq[n]+1
sdict= sorted(words_freq.items(), key=operator.itemgetter(1),reverse=True) #내림차순 정렬 딕셔너리=>리스트, value값 기준 정렬
for s in sdict:
print(s)
코드 설명
편의상 데이터 정제하는 구간이랑 명사 추출+빈도수 검사하는 구간으로 나눠서 설명하겠다.
데이터 정제
판다스로 파일을 읽어온다. 이때 데이터는 '데이터 프레임'이라고 판다스에서 사용하는 데이터 단위이다. 일단 리스트나 딕셔너리처럼 어떤 데이터 타입도 아니다. 한줄 씩 읽을 때 비로소 안에 들어있는 값(숫자가 들어있으면 int나 double, 문자열이 들어있으면 str 등)이 나온다.
file="/drive/MyDrive/test2.txt"
df=pd.read_csv(file, sep="\t", encoding="utf-8")
data=[]
데이터에서 쓸모없는 문자들을 저장한 리스트다. 처음에 문자열만 만들었더니 'ㅋ'이나 'o'같은 글자가 너무 많아서 문자 리스트도 하나 만들었다.
#문자열에서는 삭제할 문자가 없어도 에러 안뜨는데 리스트는 뜬다
deleteS=['ㅜ', 'ㅠ','ㅋ','ㅇ','𐌅','ㅗ'] #문자
deleteL=['이모티콘','삭제된', '메시지','사진', '동영상'] #문자열
데이터 프레임은 이렇게 생겼는데 한줄 씩 읽어오면 문자열로 읽힌다. 그런데 일단 문자열로 읽어오면 데이터 정제가 어려워서 리스트로 받아왔다.

#데이터 정제- 필요없는 데이터들 지우기
for i in range(len(df)):
l=df.iloc[i,0].split('] ') #리스트로 반환
원래 텍스트 파일은 아래와 같은데 이러면 입력 데이터를 두 개로 나눌 수 있다.
- ====날짜====
- [사용자 이름] [시간] [대화 내용]

split을 했을 때 다행히 ']'가 없어도 오류가 안 뜬다. 이러면 데이터를 간단하게 처리할 수 있다.
- 리스트에 들어가면 길이가 1인 리스트가 된다. 그래서 len(1)>1을 쓰면 불필요한 1번 입력데이터를 배제할 수 있다.
- 우리가 필요한 데이터는 [대화 내용] 뿐이다. 그러므로 리스트 0번 1번을 지워주면 된다.

if len(l)>1:
l.pop(0); l.pop(0) #날짜, 사용자 정보 제거
불필요한 문자열을 삭제한다. 이때 모두 사라지면 길이가 0이 될텐데 그럴 경우를 제외하고 리스트의 요소를 문자열로 변환한다. 이러면 문자 단위로 불필요한 데이터를 제거할 수 있다.
for d in deleteL:
if d in l: l.remove(d)
if len(l)!=0:
result = str(l[0])
for d in deleteS: result=result.replace(d,'')
마지막으로 불필요한 데이터를 제거한 결과가 비어있지 않다면 변수에 추가한다.
if not result.isspace() and len(result)!=0: data.append(result)
여기까지하면 txt파일에서 불필요한 정보들을 제거한 문자열의 리스트가 나온다.

명사 추출 + 빈도수 검사
konlpy에는 굉장히 다양한 모듈이 있는데 각각의 특징이 있으므로 적절한 모델을 사용하면 된다. 나의 경우 그냥 빠른 게 좋아서 okt를 사용했다.
nouns()는 문자열에서 명사만 추출해서 리스트로 반환한다. 그러다보니 명사가 없는 문자열의 경우가 생기는데, 그러면 for문 자체가 안 돌아가는 듯, 오류는 나지 않으니까 신경쓰지 말자.
#명사만 추출+빈도수 확인
for d in data:
n_list=okt.nouns(d)
길이를 1로 설정한 이유는 의미 없는 단어 다수가 상위권에 위치했기 때문이다.
빈도수는 딕셔너리를 이용했다. 딕셔너리 키값 안에 단어가 없으면 키값을 추가하고 1로 초기화한다. 있으면 그냥 해당 키값의 value를 +1을 해준다.
for n in n_list:
if len(n)>1:
if n not in list(words_freq.keys()): words_freq[n]=1
else: words_freq[n]=words_freq[n]+1
딕셔너리 정렬을 해주고 출력해준다.
sdict= sorted(words_freq.items(), key=operator.itemgetter(1),reverse=True) #내림차순 정렬 딕셔너리=>리스트, value값 기준 정렬
for s in sdict:
print(s)
추가
업데이트 전 카톡 파일을 받았는데, 파일을 살펴보니 처음부터 최신(업데이트 이후 카톡 파일)까지 전부 업데이트 전 파일 형태를 띄고 있었다. 그래서 코드를 살짝 수정했다.
#업데이트 전 카톡 분석
import pandas as pd
file="/drive/MyDrive/KakaoTalkChats.txt"
df=pd.read_csv(file, sep="\t", encoding="utf-8")
data=[]
#문자열에서는 삭제할 문자가 없어도 에러 안뜨는데 리스트는 뜬다
deleteS=['ㅜ', 'ㅠ','ㅋ','ㅇ','𐌅','ㅗ'] #문자
deleteL=['이모티콘','삭제된', '메시지','사진', '동영상'] #문자열
name="쏘융 삐쟁이"
#데이터 정제- 필요없는 데이터들 지우기
for i in range(len(df)):
l=df.iloc[i,0].split(', ') #리스트로 반환
if len(l)>1:
del l[0] #날짜 정보 제거
if len(l)>=1:
l_str = str(l[0])
l2=l_str.split(' : ')
if l2[0] == name: #특정 사용자만
#불필요한 문자 삭제
for d in deleteL:
if d in l2: l2.remove(d)
if len(l2)>1:
result = str(l2[1])
for d in deleteS: result=result.replace(d,'')
if not result.isspace() and len(result)!=0: data.append(result) #그래도 공백..
# for d in data: #리스트
# print(d)
#명사만 추출, 빈도수 계산
from konlpy.tag import Okt
import operator
okt=Okt()
words_freq={}
#명사만 추출+빈도수 확인
for d in data:
n_list=okt.nouns(d)
for n in n_list:
if len(n)!=1:
if n not in list(words_freq.keys()): words_freq[n]=1
else: words_freq[n]=words_freq[n]+1
sdict= sorted(words_freq.items(), key=operator.itemgetter(1),reverse=True) #내림차순 정렬 딕셔너리=>리스트, value값 기준 정렬
for s in sdict:
print(s)필요한 개선 사항
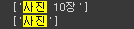
1. 최빈다 단어 에 자리한 '사진'은 사실 데이터 정제가 덜 된 거다. 리스트 단위로 문자열을 처리해서 생긴 문제인데, 대게 단순한 문제인데 어떻게 처리할까 고민 중이다.
2. 코드가 좀 지저분하다. 좀 예쁘게 정리할 수 있을 것 같은데 좀 귀찮음..
3. 사진이랑 동영상 단어를 지우는데, 사진이랑 동영상을 실제로 보내는 게 아니라 업무?때문에 그런 단어를 자주 사용하는 경우에는 최빈다 단어로 쓸 수 없다. 이런 경우 어떡할까.
'python' 카테고리의 다른 글
| [코딩] 여러 파일에서 특정 키워드를 포함하는 파일 찾기(python) (0) | 2022.03.05 |
|---|---|
| [코딩] 넘파이 모듈을 사용하지 않고 행렬곱 코드 짜기(python) (0) | 2022.03.05 |
| [python] konlpy 모듈 돌려버리기★colab에서 구글 드라이브 파일 가져오기 (0) | 2021.11.17 |
| [자료구조] 리스트 (0) | 2021.04.04 |
| 터틀 그래픽 함수 정리 (0) | 2021.03.03 |



