크롤링이라는 말만 들어봤던 소곡이. 꺄~악~ 어떻게 너무 설레~ 물론 구라다.

<전체 코드>
from selenium import webdriver
from selenium.webdriver import ActionChains
import urllib
import pandas as pd
class Netflix_content_crawling_class:
def __init__(self, word_list):
self.word_list=word_list
self.word_key=0
self.content_key=0
self.driver=None
self.content_list=[]
self.casting_list=[]
self.genre_list=[]
self.feature_list=[]
def login(self, id, pw):
print("넷플릭스 접속 중...")
# 크롬 드라이버 경로 지정
self.driver = webdriver.Chrome('C:/Users/User/chromD/chromedriver.exe')
# get 명령으로 접근하고 싶은 주소 지정
url="https://www.netflix.com/browse"
self.driver.get(url) #브라우저 접속
#로그인
self.driver.implicitly_wait(3) #대기
self.driver.find_element_by_id('id_userLoginId').send_keys(id) #id값
self.driver.find_element_by_id('id_password').send_keys(pw)
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div[3]/div/div/div[1]/form/button').click() #로그인 버튼
self.driver.implicitly_wait(3)
#넷플릭스 시청할 프로필 선택
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[2]/div/div/ul/li[1]/div/a/div/div').click() #프로필 버튼
self.driver.implicitly_wait(3)
print("넷플릭스 접속 완료")
def image_crawling(self, w):
img_list=[]
for i in range(5):
img=self.driver.find_element_by_xpath('//*[@id="title-card-0-'+str(i)+'"]/div[1]/a/div[1]/img').get_attribute('src')
img_list.append(img)
path="저장할 로컬 주소"+str(i+1)+".png"
urllib.request.urlretrieve(img, path)
img=""
return img_list
def content_crawling(self, w, image_list):
print(str(self.word_key)+"/4 번 째 단어 콘텐츠 크롤링 중...")
for i in range(5):
self.content_key+=1
#_____________________title, story, image__________________________________
content=[] #키값, word_key값, 제목, 줄거리, 이미지
content.append(self.content_key) #키값
content.append(self.word_key) #word_key값
title=""
title=self.driver.find_element_by_xpath('//*[@id="title-card-0-'+str(i)+'"]/div[1]/a/div[1]/div/p').text #제목
content.append(title)
#모달 이동
modal=self.driver.find_element_by_css_selector("#title-card-0-"+str(i)+" > div.ptrack-content").click()
self.driver.implicitly_wait(2)
self.driver.get(self.driver.current_url) #모달창으로 이동
self.driver.implicitly_wait(3)
story=""
try:
story=self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[2]/div/div[3]/div/div[1]/div/div/div[1]/p/div').text #줄거리
content.append(story)
except Exception as e:
content.append("NULL")
content.append(image_list[i])
self.content_list.append(content)
content.clear #초기화
#__________________casting, genre, feature___________________
right_modal_list=self.driver.find_elements_by_class_name('previewModal--tags') #오른쪽 출연, 장르, 특징 모두 크롤링
content_feature_list=[]
try:
for i in range(3):
content_feature_list.append(list(right_modal_list[i].text.split(', ')))
except Exception as e:
pass
right_modal_list=[] #초기화
#필요없는 문자 제거//여기서 정하자! 출연진,장르, 특징 뒤섞이는 거 방지
for c in content_feature_list:
if '더 보기' in c: c.remove('더 보기')
edit=c[0].split(': ')
c.pop(0)
c.insert(0, edit[0]); c.insert(1, edit[1])
#출연진
casting=[self.content_key]
try:
if content_feature_list[0][0]=="출연": #index out of range
del content_feature_list[0][0]
for c in content_feature_list[0]:
casting.append(c)
self.casting_list.append(casting)
casting.clear; casting=[self.content_key]
else:
casting.append("NULL")
self.casting_list.append(casting)
except IndexError:
pass
#장르
genre=[self.content_key]
try:
if content_feature_list[1][0]=="장르": #index out of range
del content_feature_list[1][0]
for c in content_feature_list[1]:
genre.append(c)
self.genre_list.append(genre)
genre.clear; genre=[self.content_key]
else:
genre.append("NULL")
self.genre_list.append(genre)
except IndexError:
pass
#콘텐츠 특징
feature=[self.content_key]
try:
if content_feature_list[2][0]=="시리즈 특징" or content_feature_list[2][0]=="영화 특징": #index out of range
del content_feature_list[2][0]
for c in content_feature_list[2]:
feature.append(c)
self.feature_list.append(feature)
feature.clear; feature=[self.content_key]
else:
feature.append(w)
self.feature_list.append(feature)
except IndexError:
pass
self.driver.back() #뒤로가기
self.driver.implicitly_wait(3)
print("#", end="")
print("\n"+str(self.word_key)+"/4 번 째 단어 콘텐츠 크롤링 완료")
def save(self):
print("데이터 저장 중...")
content_df=pd.DataFrame(self.content_list, columns=['key', 'word_Key', 'title', 'story', 'img']) #데이터 프레임에 크롤링한 정보 입력,
casting_df=pd.DataFrame(self.casting_list,columns=['key', 'name'])
genre_df=pd.DataFrame(self.genre_list, columns=['key', 'genre'])
feature_df=pd.DataFrame(self.feature_list,columns=['key','feature'])
content_df.to_csv("저장할 로컬 주소/파일 이름.csv", header=False, encoding='euc-kr', index=False) #저장할 로컬 주소
casting_df.to_csv("저장할 로컬 주소/파일 이름.csv", header=False, encoding='euc-kr', index=False)
genre_df.to_csv("저장할 로컬 주소/파일 이름.csv", header=False, encoding='euc-kr', index=False)
feature_df.to_csv("저장할 로컬 주소/파일 이름.csv", header=False, encoding='euc-kr', index=False)
print("데이터 저장 완료")
def run(self):
self.login() #로그인 id, pw전달
for w in self.word_list:
self.word_key+=1
try:
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[1]/div/div/div/div[1]/div/button').click() #검색창 클릭
except Exception as e:
pass
self.driver.find_element_by_name("searchInput").send_keys(w) #키워드 검색
try :
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[1]/div/div/div/div[1]/div/div/span[1]').click() #검색창 클릭
except Exception as e:
pass
image_list=self.image_crawling(w) #이미지 크롤링
self.content_crawling(w,image_list) #콘텐츠 크롤링
self.driver.back()
self.save()
print("콘텐츠 정보 크롤링 완료")
test_list=['우리', '수업', '사람', '담배'] #카카오톡 최빈다 단어 상위 4개 리스트
test=Netflix_content_crawling_class(test_list)
test.run()
크롤링?
웹 상에 존재하는 데이터들을 긁어오는 행위다.
- 정적인 페이지 : 네이버 기사 홈페이지 등. => Beautiful Soup 모듈
- 동적인 페이지 : 넷플릭스 등. 모달(modal) 창과 여러 새 창들이 자주 등장함. => Selenium 모듈
처음에 정적인 페이지, 동적인 페이지 아무 것도 모르고 뷰리풀 스프 모듈 썻다가 하루동안 개고생했다. 여러분들은 지금 자기가 크롤링 하려는 웹페이지가 정적인지, 동적인지 확인하시고 시작하길 바랍니다.
들어가기 전 기초 지식
1. (vscode) jupyter로 코드 짜기.
: 크롤링을 하면 새로운 창에 접속하게 되는데 이 창은 코드가 끝나면 닫힌다. 즉, 한 번 코드를 돌릴 때마다 창이 열리고 닫히는데 이게 반복되면 시스템 부하가 올 수 도 있고, 일단 기다리는게 무진장 지루하다. 주피터로 돌리면 창이 계속 열려있으니 크롤링할 때는 주피터를 추천한다.
https://sogogi1000inbun.tistory.com/66
[IDE] vscode에서 jupyter 사용하기
python을 쓰다보면 불편한 게 있다. 코드를 돌릴 때 중간에 이 코드가 맞게 돌아가는 지 확인하고 싶은데 그러기 위해서는 싹 다 돌려야 된다는 거다. 아 불편한데?;; 그래서 vscode로 jupyter notebook
sogogi1000inbun.tistory.com
2. 개발자 모드
: 웹페이지에서 F12를 누르면 html 코드가 나오는데 이때, 상단바 가장 왼쪽을 클릭하면 요소들을 선택하여 해당 요소의 코드, xpath 경로(우클릭>copy>xpath, element, selector 등) 등을 볼 수 있다.
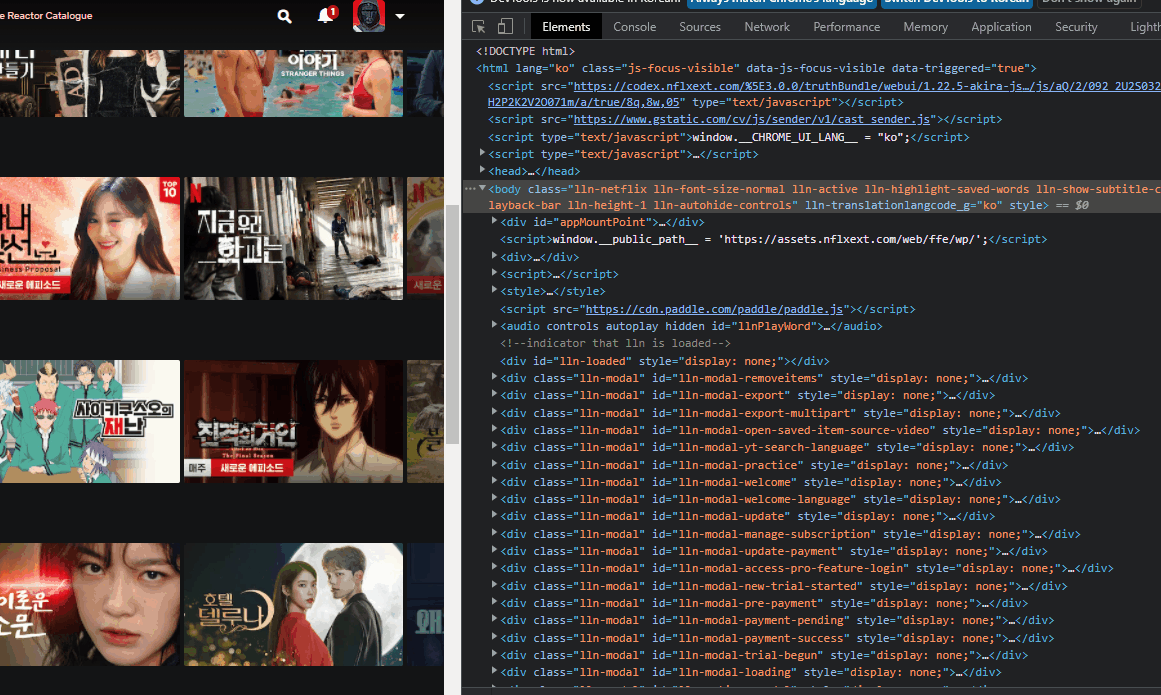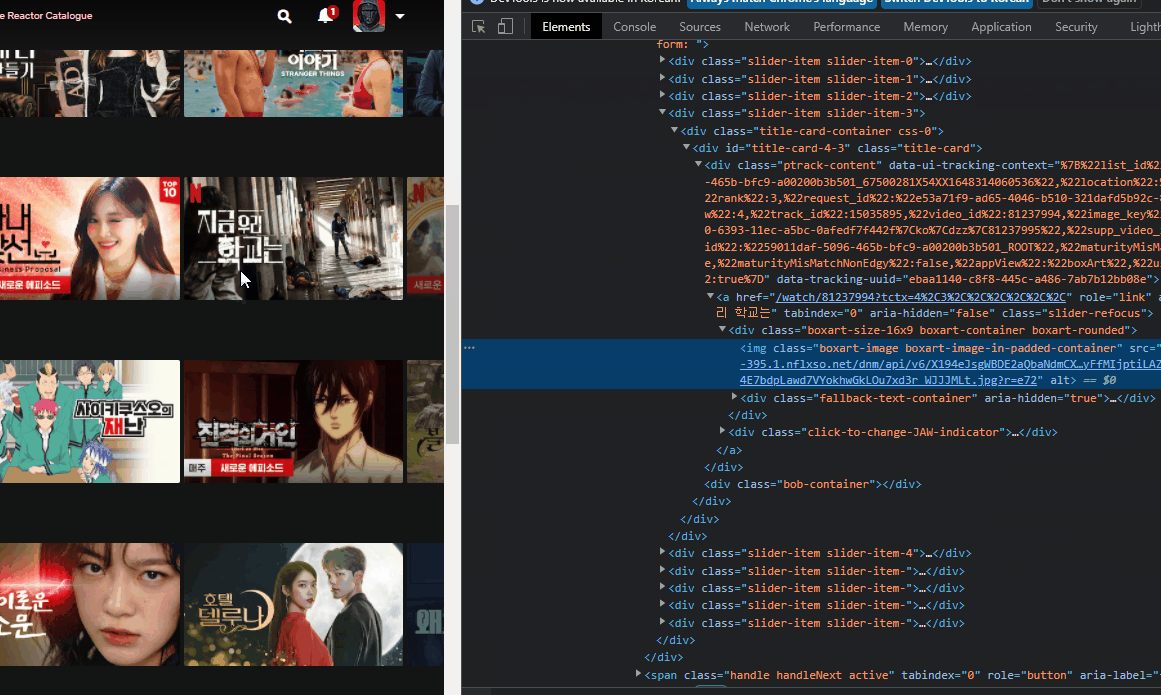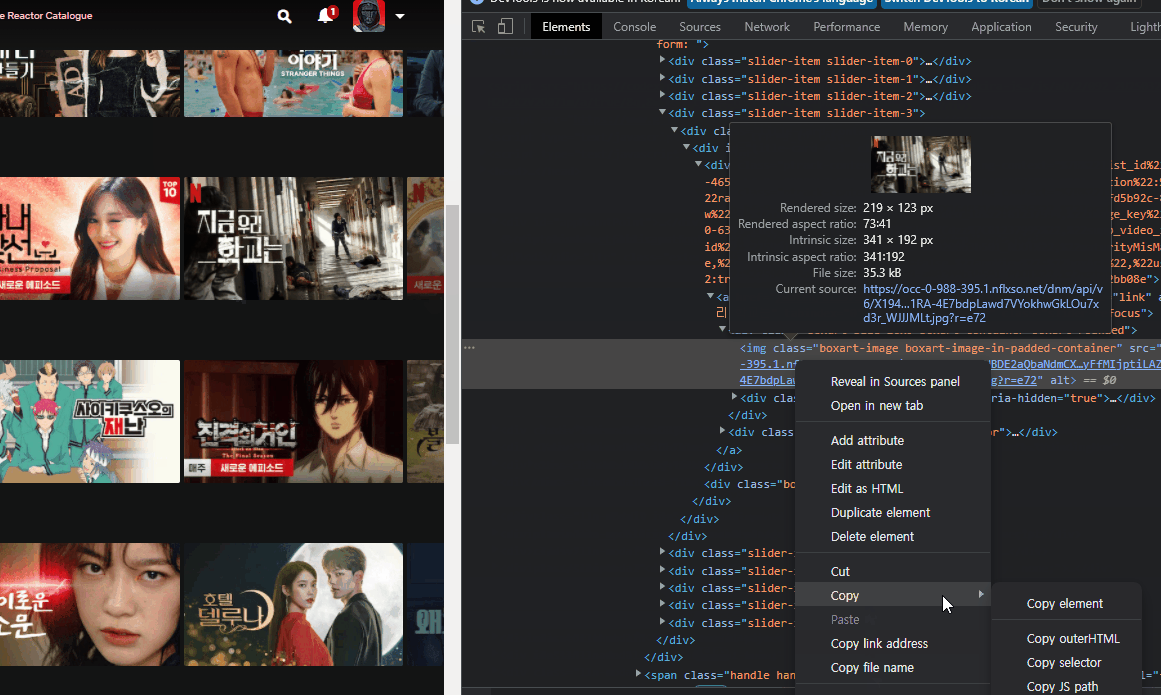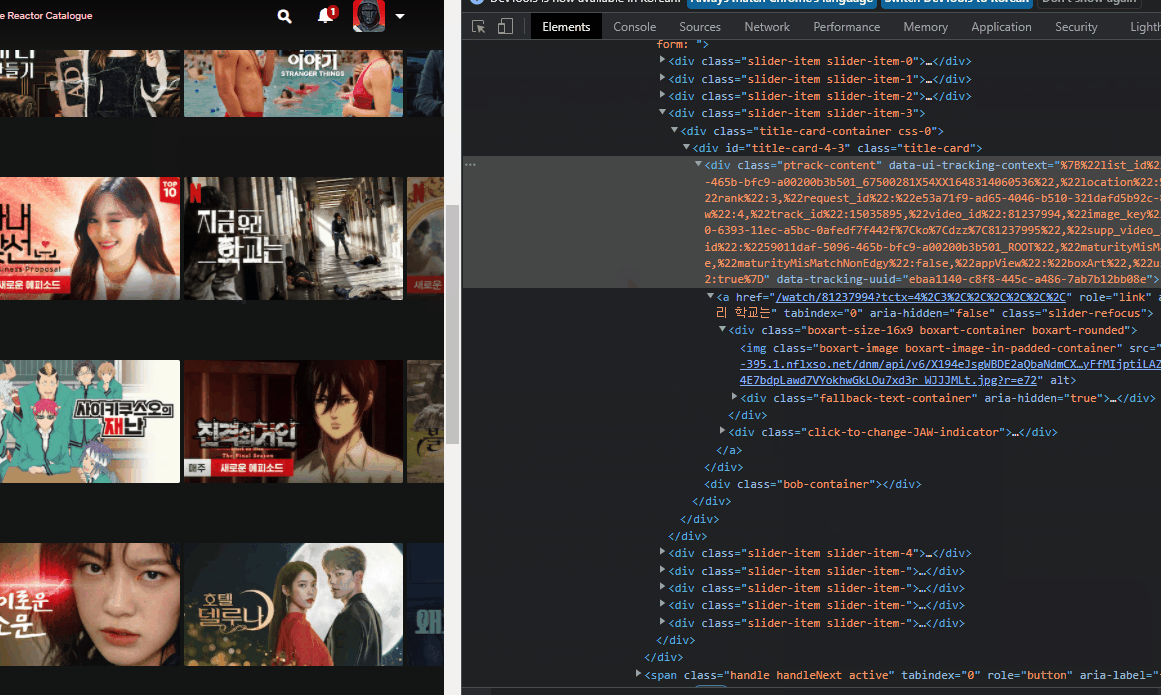
3. chrome drvier
: 크롬 드라이버 설정을 해줘야 한다. 자세한 건 검색해보길 바란다.
https://chromedriver.chromium.org/downloads
ChromeDriver - WebDriver for Chrome - Downloads
Current Releases If you are using Chrome version 100, please download ChromeDriver 100.0.4896.20 If you are using Chrome version 99, please download ChromeDriver 99.0.4844.51 If you are using Chrome version 98, please download ChromeDriver 98.0.4758.102 Fo
chromedriver.chromium.org
솔직히 왜 크롬 드라이버를 설정해줘야 하는 지 몰랐는데, 이번 학기 <운영체제론> 과목을 수강하면서 알게 되버렸다. 교수님께서 아는 드라이버 다 말해보라고 하시길래 크롬 드라이버 이야기를 했더니ㅋㅋ 우리 교수님께서는 내 개소리에도 친절하게 답변해주셨다.

요약하자면, 웹을 크롬처럼(인터넷 익스플로어, 파이어 폭스처럼도 가능) 자동으로 작동 시키기위해 사용하는 것 같다.
4. xpath(XML path Language)
: xpath란 xml 문서의 특정 요소나 속성에 접근하기 위한 경로를 지정하는 언어다.(라고 tcp school이 말씀해주셨습니다.) 코드를 보면 driver.find_element_by_xpath()가 자주 보일텐데, 쉽게 말해서 넷플릭스에 나열된 콘텐츠에 접근하기 위한 경로다. 보통 한 줄에 콘텐츠가 있으면 하나만 다른 경우가 많다.
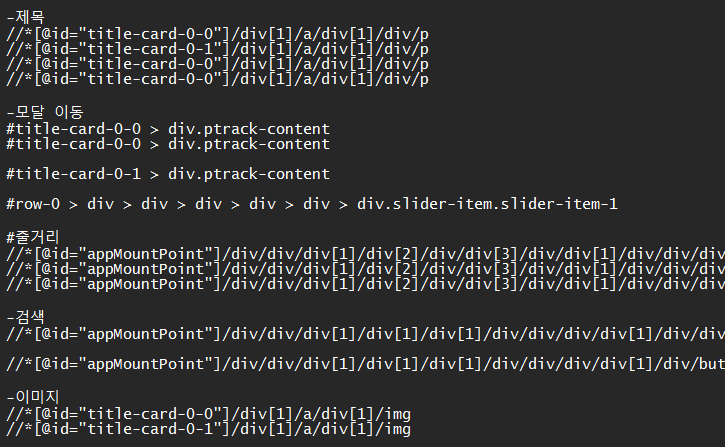
그래서 나는 메모장에 처음 콘텐츠, 옆에 콘텐츠 xpath를 비교해서 다른 부분을 체크했다. 무슨 말인지 잘 모르겠으면 공부하고 와라 아래 글 읽어보면서 혹은 실습해보면서 이해하길 바란다.
5. 가끔 잘 되다가 안 될 때가 있을텐데, 그건 vscode나 ide 창을 한 번 닫았다가 다시 작동시키면 잘 된다. 그래도 안 되면 컴퓨터를 재부팅시키면 된다.
코드 분석
1. 객체 선언
초기화 내용은 생략하겠다.
test_list=['우리', '수업', '사람', '담배']
test=Netflix_content_crawling_class(test_list)
test.run()
2. 로그인
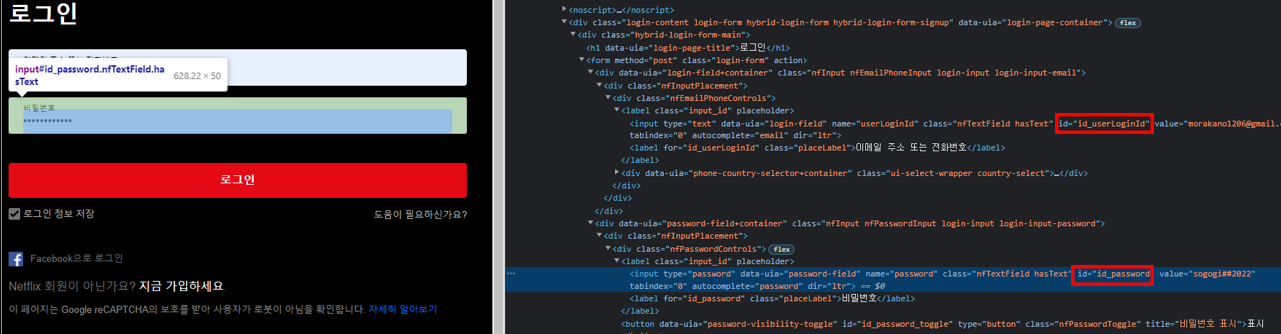
- 나는 내 넷플릭스 로그인 정보를 지정 해놨다. 인자값으로 옮기고 싶다면 코드를 수정해야 한다.
- driver.find_element_by_id() 안에 들어가는 값은 개발자 모드를 켜고 해당 id와 pw 창의 id를 적어주면 된다. html 창을 처음보면 뭐가 뭔지 잘 모를텐데 이것저것 시도해보면 웹 요소 찾는 법을 배우게 된다.
정신이 피폐해지는 건 덤.
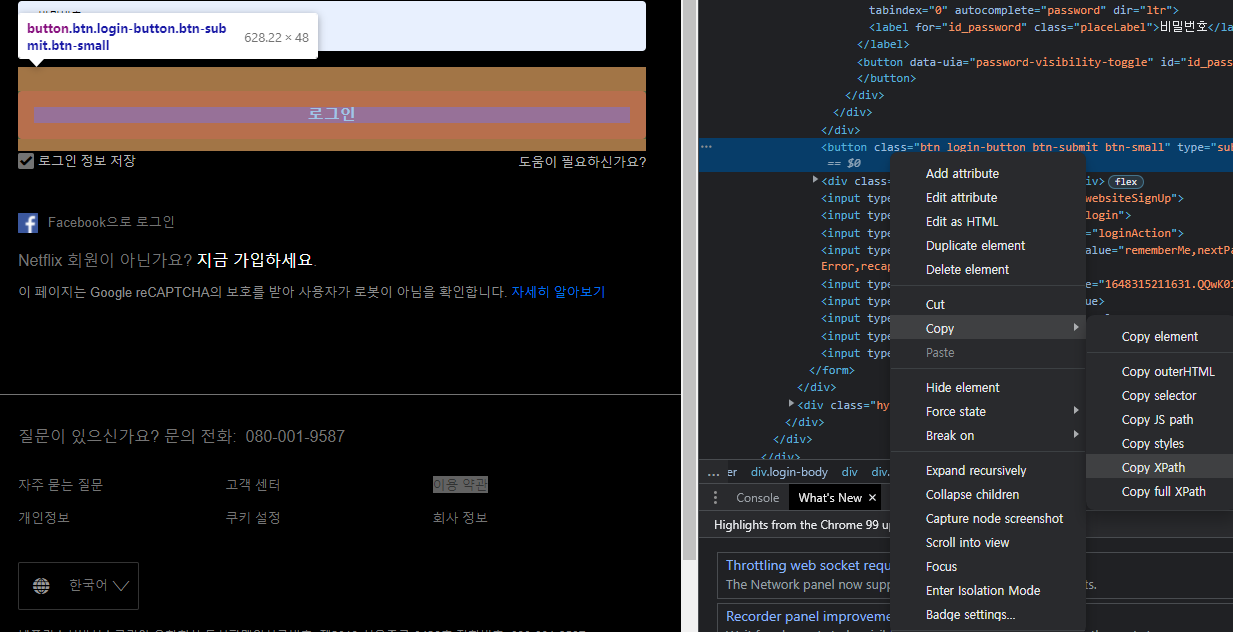
- driver.find_element_by_xpath()도 마찬가지로 로그인을 눌러야 하므로 버튼의 태그를 찾아서 xpath를 복사한다.
def login(self, id="id", pw="pw"):
print("넷플릭스 접속 중...")
# 크롬 드라이버 경로 지정
self.driver = webdriver.Chrome('C:/Users/User/chromD/chromedriver.exe')
# get 명령으로 접근하고 싶은 주소 지정
url="https://www.netflix.com/browse"
self.driver.get(url) #브라우저 접속
#로그인
self.driver.implicitly_wait(3) #대기
self.driver.find_element_by_id('id_userLoginId').send_keys(id) #id값
self.driver.find_element_by_id('id_password').send_keys(pw)
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div[3]/div/div/div[1]/form/button').click() #로그인 버튼
self.driver.implicitly_wait(3)
#넷플릭스 시청할 프로필 선택
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[2]/div/div/ul/li[1]/div/a/div/div').click() #프로필 버튼
self.driver.implicitly_wait(3)
print("넷플릭스 접속 완료")
- 로그인 하는데 시간 지연이 있으므로 driver.implicitly_wait(초단위) 를 사용하여 대기한다.
=> 앞으로 계속 이런 식의 메소드 사용만 있다. 웹에서 요소만 잘 찾으면 원하는 정보를 빠르게 찾을 수 있다.
3. 전체 흐름
- word_list는 넷플릭스에 검색할 단어들의 모음이다.
- try-except를 쓴 건, 가끔씩 저기서 에러가 계속 나서다.
- 전체 흐름 : 검색창 클릭> 키워드 검색> 이미지 크롤링> 콘텐츠 크롤링> 로컬 저장
for w in self.word_list:
self.word_key+=1 #word_key는 검색할 단어에 key를 붙인거다.
try:
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[1]/div/div/div/div[1]/div/button').click() #검색창 클릭
except Exception as e:
pass
self.driver.find_element_by_name("searchInput").send_keys(w) #키워드 검색
try :
self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[1]/div[1]/div/div/div/div[1]/div/div/span[1]').click() #검색창 클릭
except Exception as e:
pass
image_list=self.image_crawling(w) #이미지 크롤링
self.content_crawling(w,image_list) #콘텐츠 크롤링
self.driver.back()
Q. 왜 이미지 크롤링이랑 콘텐츠 크롤링을 따로 하나요??
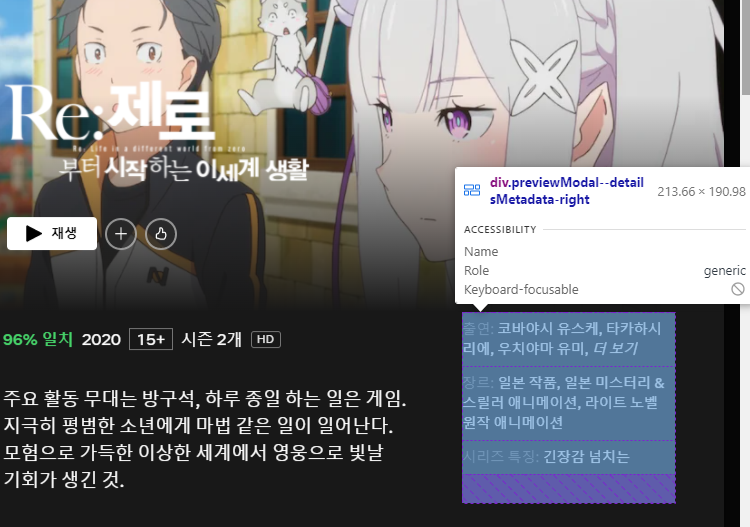
A. 넷플릭스 구조가 그렇습니다. 모달 창 열기 전에 이미지가 있고, 모달 창을 열어야 콘텐츠 정보(영상, 줄거리, 출연진, 장르, 키워드 등)가 나옵니다.
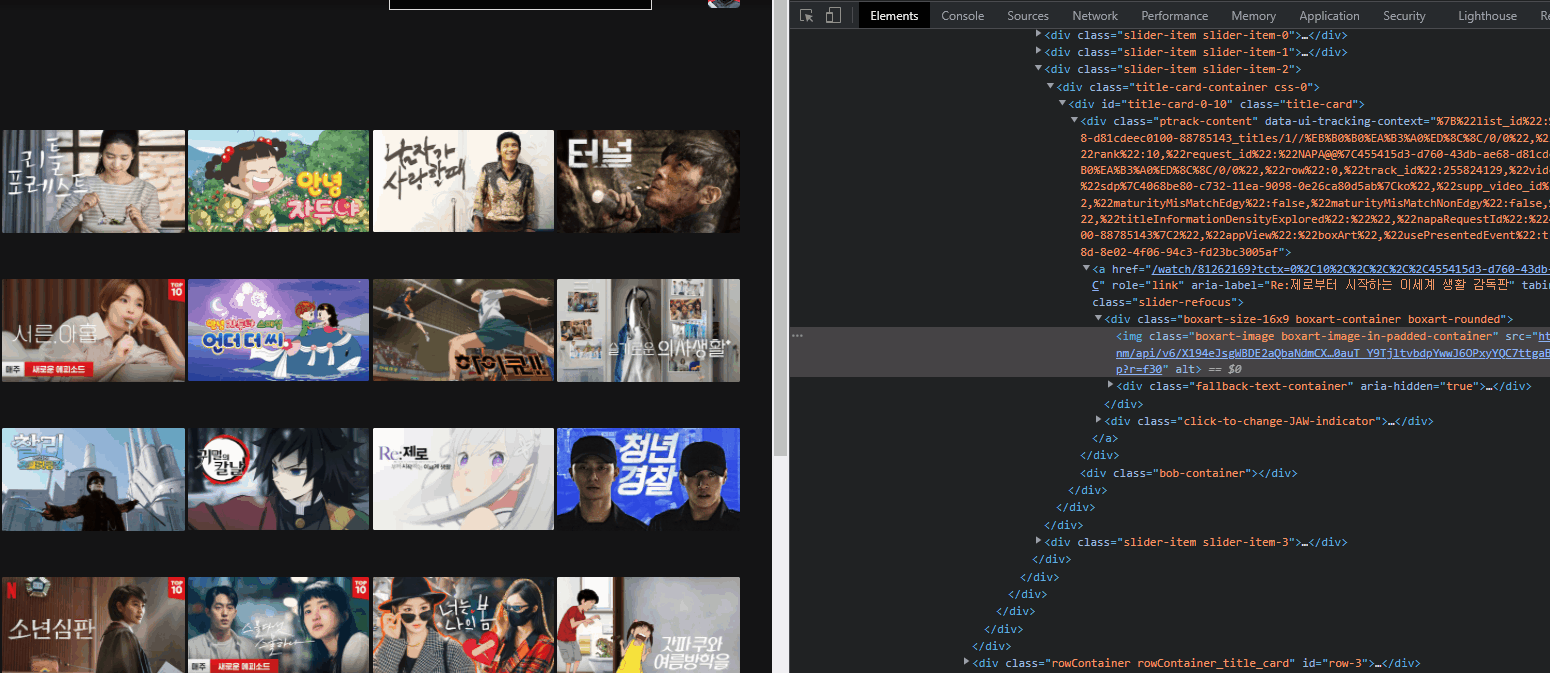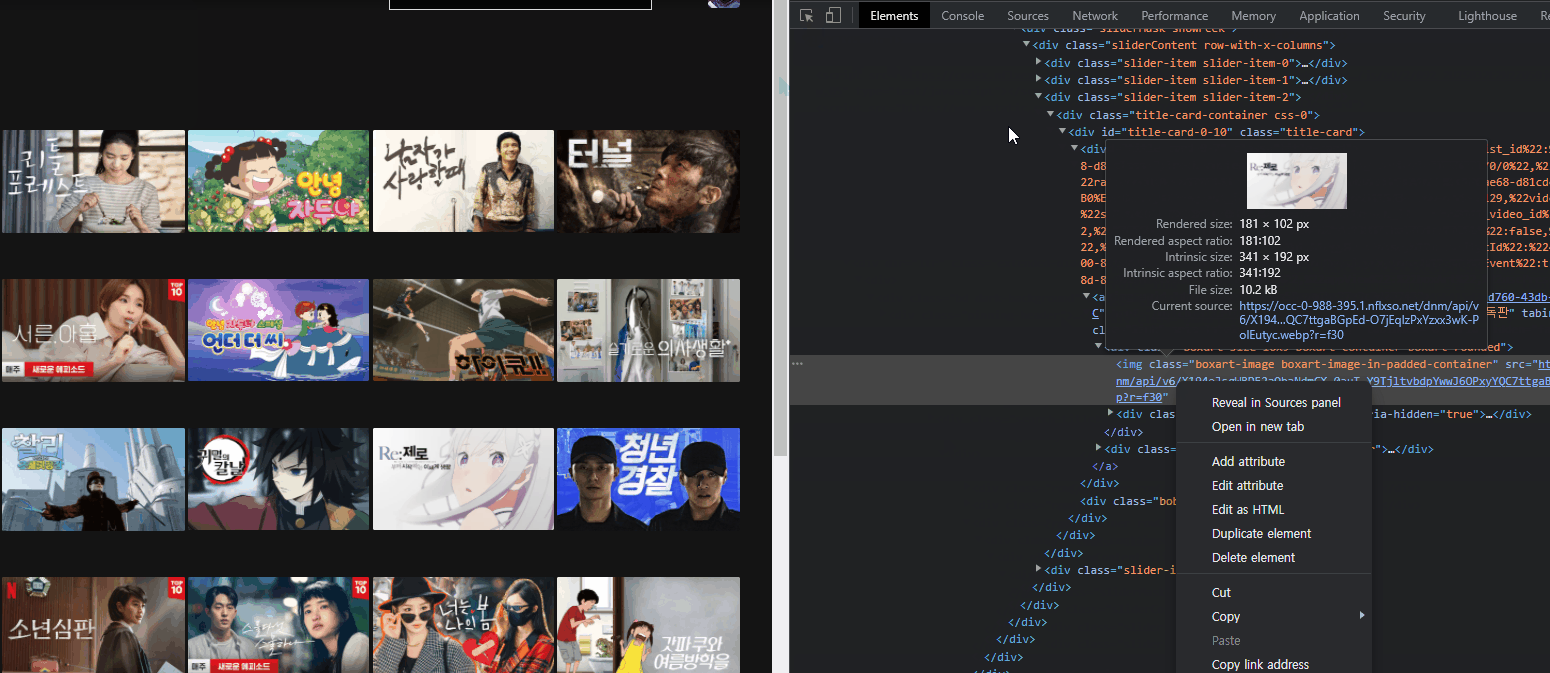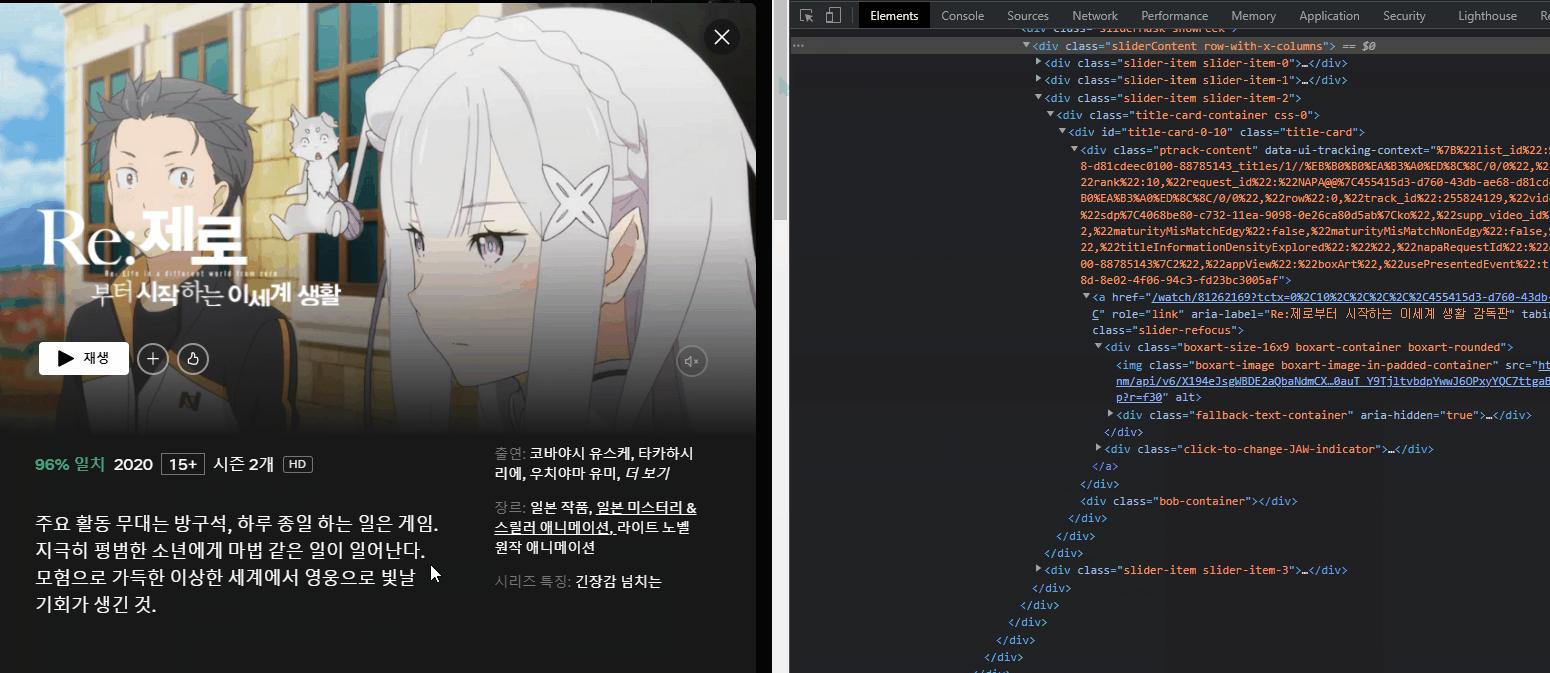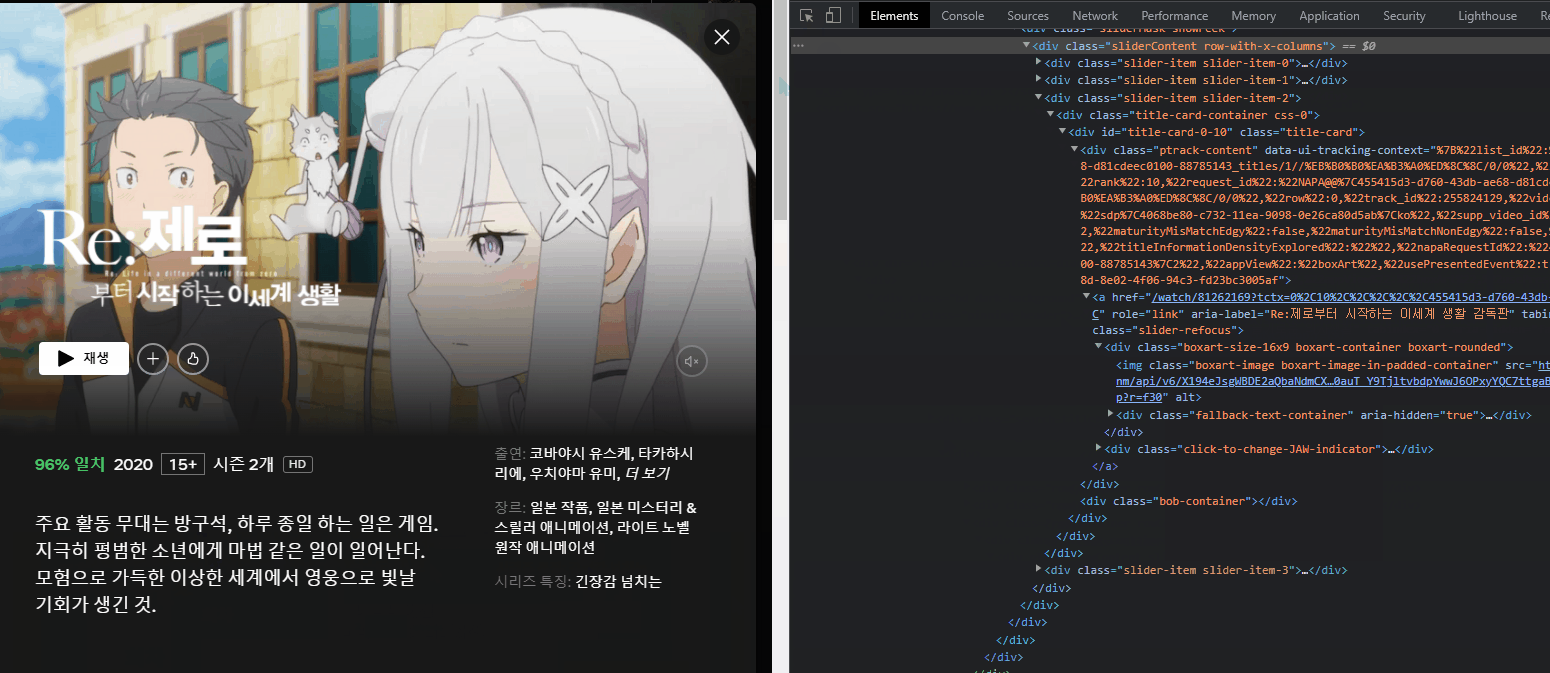
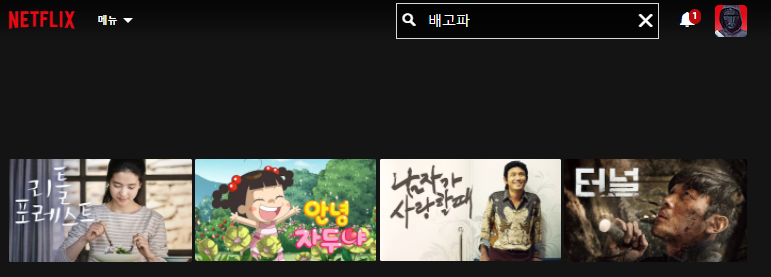
4. 이미지 크롤링
- 상위 5개의 콘텐츠만 저장할 것이기 때문에 for문은 5개로 설정한다. 이 이상하고 싶다면 2번째 줄의 xpath가 다르니까 주의해서 코딩하길 바란다.
- 이미지의 xpath를 메모장에 적어보니까 str(i) 설정해놓은 부분만 달라서, 다음과 같이 코드를 짰다.
def image_crawling(self, w):
img_list=[]
for i in range(5):
img=self.driver.find_element_by_xpath('//*[@id="title-card-0-'+str(i)+'"]/div[1]/a/div[1]/img').get_attribute('src')
img_list.append(img)
path="파일 경로"+str(i+1)+".png" #저장할 로컬 주소
urllib.request.urlretrieve(img, path)
img=""
return img_list
5-1. 콘텐츠 정보 크롤링(title, story)
- for문은 크롤링할 콘텐츠의 개수만큼 돌린다.
- title 크롤링은 이제 말 안 해도 어떻게 한 건지 알겠쥬?
- modal 이동은 이런 걸 말한다. story 크롤링은 말안으엥 알겠쥬?
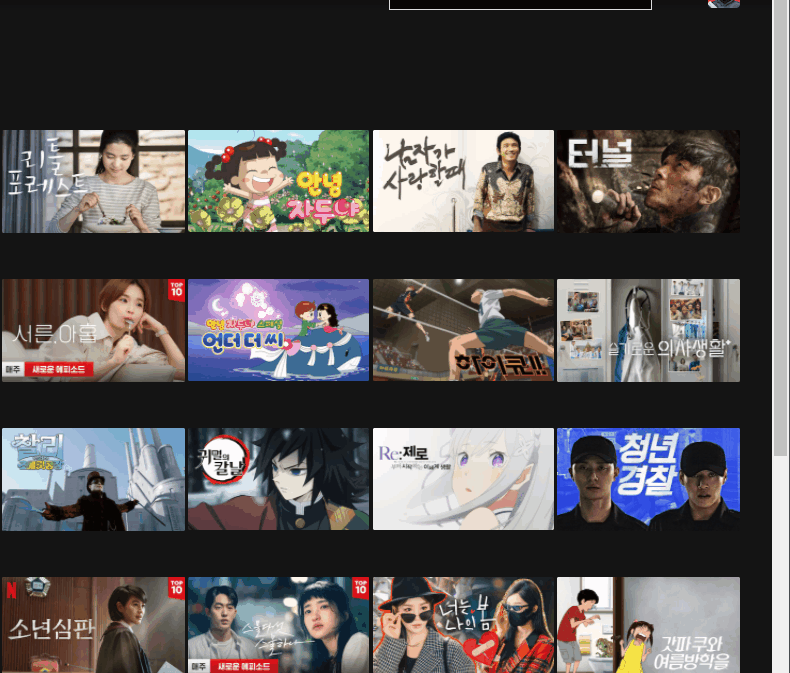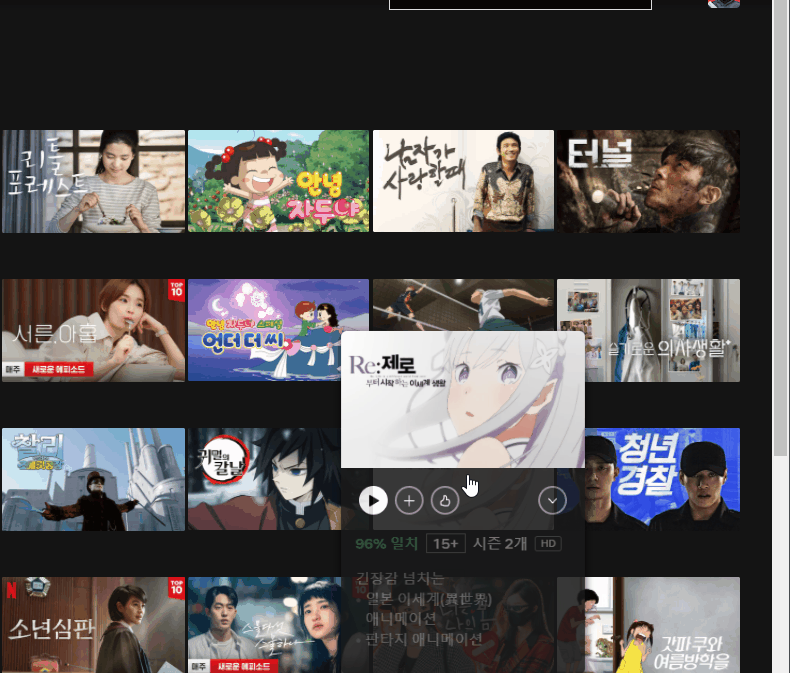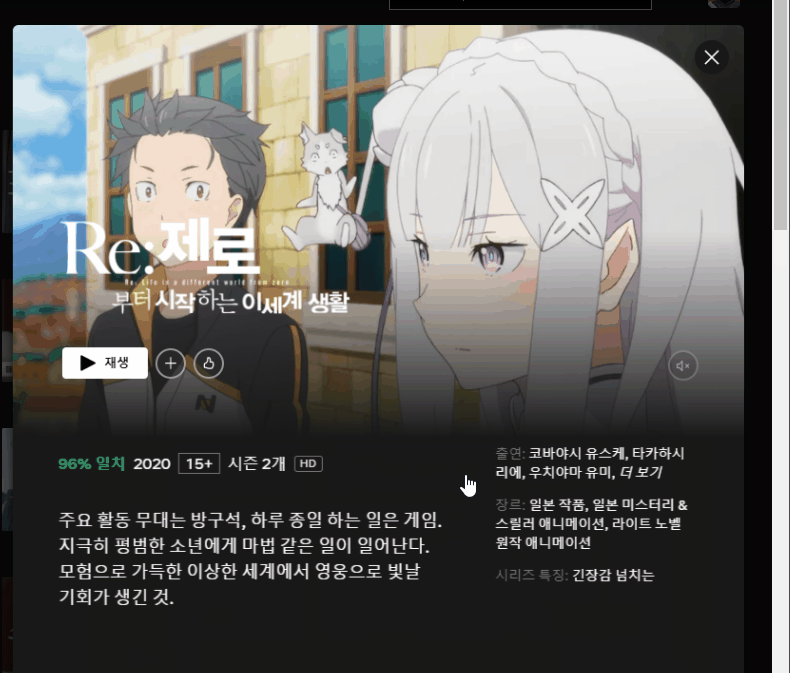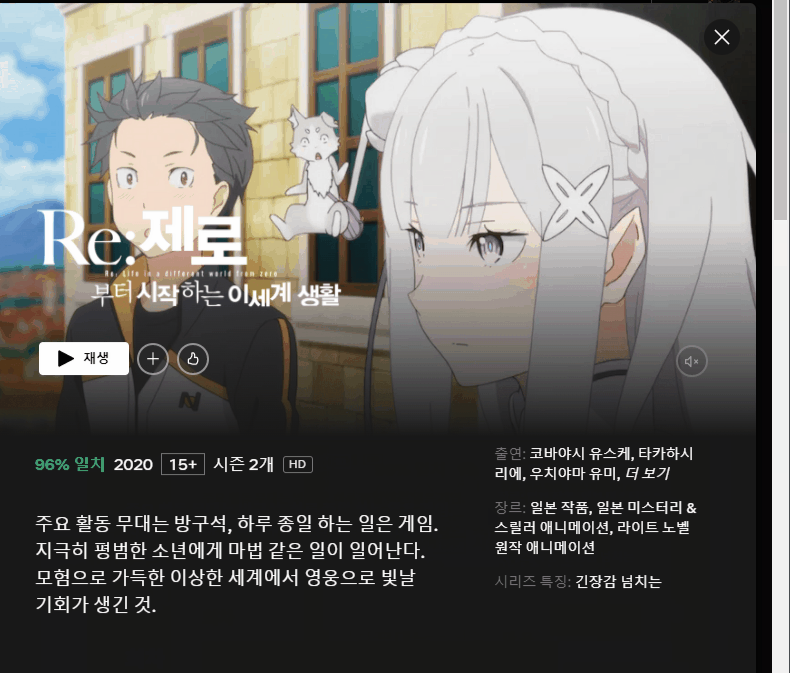
def content_crawling(self, w, image_list):
print(str(self.word_key)+"/4 번 째 단어 콘텐츠 크롤링 중...")
for i in range(5):
self.content_key+=1
#_____________________title, story, image__________________________________
content=[] #키값, word_key값, 제목, 줄거리, 이미지
content.append(self.content_key) #키값
content.append(self.word_key) #word_key값
title=""
title=self.driver.find_element_by_xpath('//*[@id="title-card-0-'+str(i)+'"]/div[1]/a/div[1]/div/p').text #제목
content.append(title)
#모달 이동
modal=self.driver.find_element_by_css_selector("#title-card-0-"+str(i)+" > div.ptrack-content").click()
self.driver.implicitly_wait(2)
self.driver.get(self.driver.current_url) #모달창으로 이동
self.driver.implicitly_wait(3)
story=""
try:
story=self.driver.find_element_by_xpath('//*[@id="appMountPoint"]/div/div/div[1]/div[2]/div/div[3]/div/div[1]/div/div/div[1]/p/div').text #줄거리
content.append(story)
except Exception as e:
content.append("NULL")
content.append(image_list[i])
self.content_list.append(content)
content.clear #초기화
5-2. 콘텐츠 정보 크롤링(casting, genre, feature)
- 여기서 좀 골머리를 썩었다. 출연, 장르, 시리즈 특징을 일일이 크롤링할 생각을 했는데, 클래스 이름은 같고 xpath는 하나가 맨 끝에 하나가 다른데. 일단 html 구조가 좀 귀찮게 생겼다.


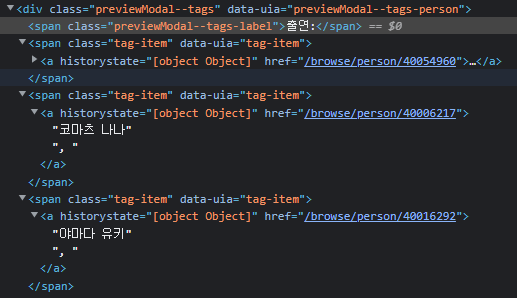
- 그래서 그냥 통으로 가져왔다. 근데 리스트 안에 출연/장르/시리즈 특징만 있는 건 또 아니여서 3개만 따로 분리해준다.
- 출연을 잘 보면 마지막이 '더 보기'이다. 제거해준다
- 이렇게 가져오면 아래처럼 되는데, 이건 ':'를 제거해준다. 위에서 언급했던 장르와 출연 이런식으로 데이터가 뒤섞이는 것을 방지하기 위해 출연과 장르는 제거하지 않고 0번 인덱스에 저장해준다.

#__________________casting, genre, feature___________________
right_modal_list=self.driver.find_elements_by_class_name('previewModal--tags') #오른쪽 출연, 장르, 특징 모두 크롤링
content_feature_list=[]
try:
for i in range(3):
content_feature_list.append(list(right_modal_list[i].text.split(', ')))
except Exception as e:
pass
right_modal_list=[] #초기화
#필요없는 문자 제거//여기서 정하자! 출연진,장르, 특징 뒤섞이는 거 방지
for c in content_feature_list:
if '더 보기' in c: c.remove('더 보기')
edit=c[0].split(': ')
c.pop(0)
c.insert(0, edit[0]); c.insert(1, edit[1])
#출연진
casting=[self.content_key]
try:
if content_feature_list[0][0]=="출연": #index out of range
del content_feature_list[0][0]
for c in content_feature_list[0]:
casting.append(c)
self.casting_list.append(casting)
casting.clear; casting=[self.content_key]
else:
casting.append("NULL")
self.casting_list.append(casting)
except IndexError:
pass- 아 근데 여기서 재밌는 사실을 알아냈다. 한 행의 데이터가 출연/장르 시리즈 특징인지 구분하기 위해 0번 인덱스에 데이터 이름을 넣었는데, 데이터를 집어 넣을 때는 그 정보가 필요없으므로 0번 인덱스를 지워야 했다. 처음에 pop으로 지웠는데 한 행이 통으로 날아가고 index out of range 에러가 나더라. 그래서 del로 지워 줬다.
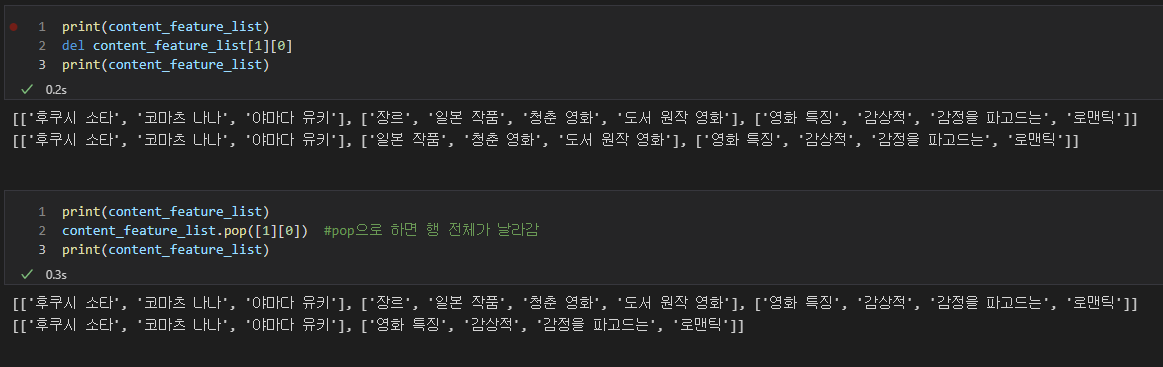
- 콘텐츠 특징의 경우 그 이름이 '시리즈 특징'으로 되있는 경우도 있고, '영화 특징'으로 되있는데도 있어서 둘 다 설정해줬다. 캐스팅과 장르와 다르게 해당 정보가 없을 경우 "NULL"을 넣어주는게 아니라, 콘텐츠를 검색한 단어가 들어간다.
#콘텐츠 특징
feature=[self.content_key]
try:
if content_feature_list[2][0]=="시리즈 특징" or content_feature_list[2][0]=="영화 특징": #index out of range
del content_feature_list[2][0]
for c in content_feature_list[2]:
feature.append(c)
self.feature_list.append(feature)
feature.clear; feature=[self.content_key]
else:
feature.append(w)
self.feature_list.append(feature)
except IndexError:
pass
6. 로컬 저장
- 로컬 저장은 판다스로 해줬다. 원래는 빈 데이터프레임을 만들고 한 행 씩 추가해주려 했는데 왜 인지 안 돼서(append 메소드에서 리스트를 시리즈로 만들었다가 데이터프레임으로 만들어줬다가.. 다 해봤는데 안 됨) 그냥 2차원 리스트를 만들고 한꺼번에 데이터프레임으로 만들어줬다.
- to_csv()의 매개변수 의미
- header=False : 열 이름 저장을 안 하겠다.
- encoding : 인코딩 방식이다. utf-8, cp949 다 해봤는데, euc-kr만 되더라.
- index=False : 데이터 프레임을 만들면 자동으로 행 번호가 나오는데, 어차피 csv 파일로 저장하면 행번호가 다 나오기도 하고 나한테는 필요없는 데이터여서 제거 해줬다.
def save(self):
print("데이터 저장 중...")
content_df=pd.DataFrame(self.content_list, columns=['key', 'word_Key', 'title', 'story', 'img']) #데이터 프레임에 크롤링한 정보 입력,
casting_df=pd.DataFrame(self.casting_list,columns=['key', 'name'])
genre_df=pd.DataFrame(self.genre_list, columns=['key', 'genre'])
feature_df=pd.DataFrame(self.feature_list,columns=['key','feature'])
content_df.to_csv("경로/content.csv", header=False, encoding='euc-kr', index=False) #저장할 로컬 주소
casting_df.to_csv("경로/casting.csv", header=False, encoding='euc-kr', index=False)
genre_df.to_csv("경로/genre.csv", header=False, encoding='euc-kr', index=False)
feature_df.to_csv("경로/feature.csv", header=False, encoding='euc-kr', index=False)
print("데이터 저장 완료")
끗~
'python' 카테고리의 다른 글
| [코딩] 쉼표 넣는 코드 (0) | 2022.04.17 |
|---|---|
| [데이터 마이닝] 모듈? 그게 뭔데? 오직 python으로만 짜는 k-means 클러스터링 (8) | 2022.04.15 |
| [코딩] 여러 파일에서 특정 키워드를 포함하는 파일 찾기(python) (0) | 2022.03.05 |
| [코딩] 넘파이 모듈을 사용하지 않고 행렬곱 코드 짜기(python) (0) | 2022.03.05 |
| [코딩] 카카오톡 채팅방 분석, 빈도수 높은 단어 (0) | 2022.02.25 |



